1.认识urllib和urllib2模块
Python请求URL相关的操作,需要使用到相关模块,在python2中,如果不依赖于第三方框架或者模块,那么urllib和urllib2是最常用的.
通常,urllib和urllib2是联合使用的,区别于联系:
-
urllib只接收一个URL,不能设置用户代理字符串.但是urllib内置了urlencode的方法,可以把一个字典,转换成为url传输所使用的字符串.这方法在urllib2不存在.
-
urllib2可以接受一个Request对象,可以来设置一个URL的headers,伪造成浏览器正常访问.
1.1常见的用法urlopen直接接收URL
urllib2.urlopen(url[, data][, timeout])
-
urlopen方法是urllib2模块最常用也最简单的方法,它打开URL网址,url参数可以是一个字符串url或者是一个request对象。Request对象和data在request类中说明,定义都是一样的。
-
对于可选的参数timeout,阻塞操作以秒为单位
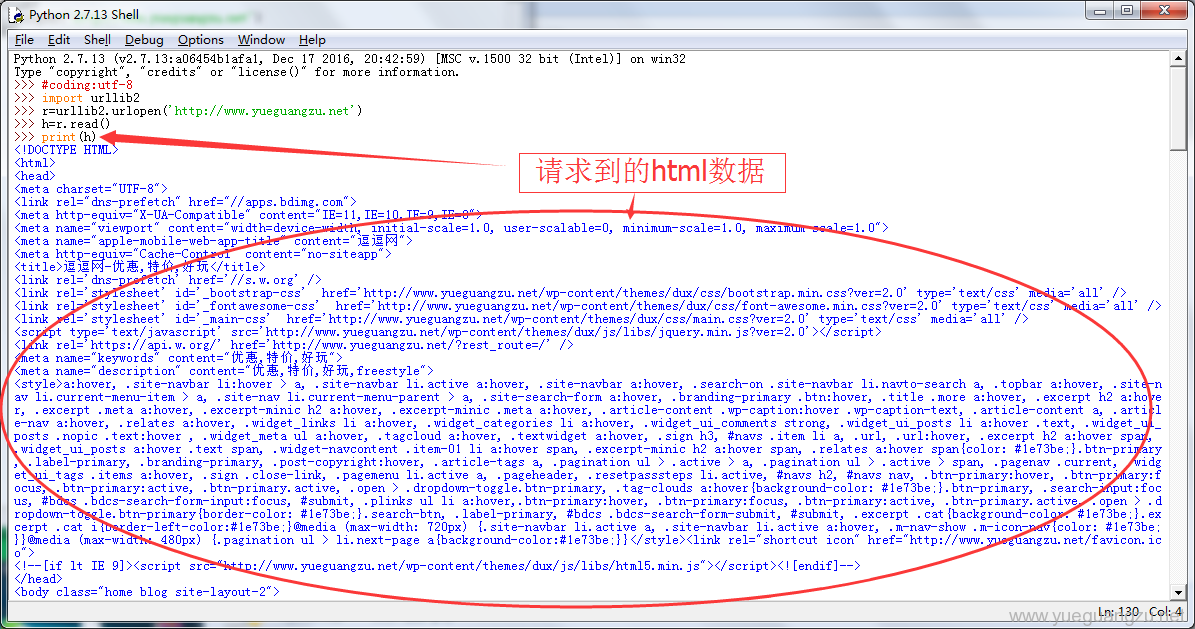
import urllib2
r=urllib2.urlopen('http://www.yueguangzu.net')
h=r.read()
如果是python3,urllib2库不是标准库,urllib2模块需要替换成urllib.request
import urllib.request
r=urllib.request.urlopen('http://www.yueguangzu.net')
h=r.read()
请求到的html报文数据
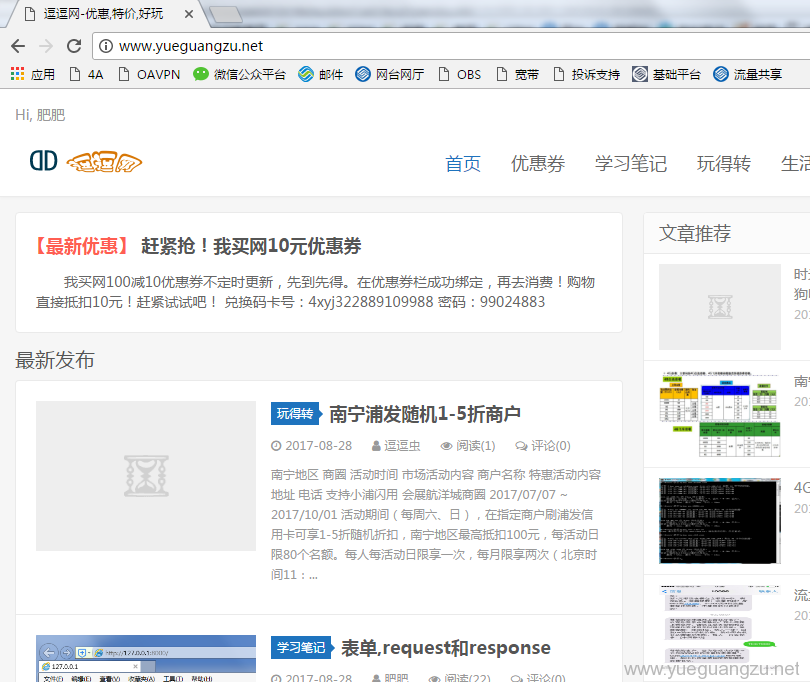
浏览器解析后的效果
1.2 urlopen接收对象
如果需要请求的页面,不支持直接访问,需要模拟浏览器访问时,则需要使用到
Request类是一个抽象的URL请求。
data是作为参数请求,如果data不等于None,则该请求为POST,否则为GET,headers是请求的头文件,是一个字典
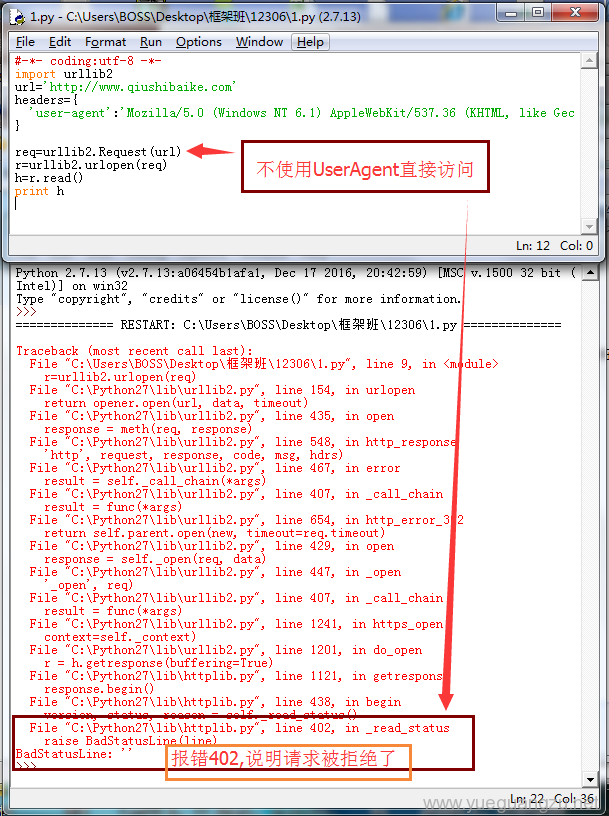
以糗事百科`https://www.qiushibaike.com为例子,该网站做了防止爬取数据的机制,对于不是浏览器访问的行为,不会响应.需要设置User-Agent(用户代理).所以需要将UA封装到一个对象,让urlopen使用带有这个UA头的对象去访问网站.
user-agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36
User-Agent:Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; Tablet PC 2.0; InfoPath.3; .NET CLR 1.1.4322)
首先需要构造一个Request包含headers,url
import urllib2
url='http://www.qiushibaike.com'
headers={
'user-agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36',
}
req=urllib2.Request(url,headers=headers)
r=urllib2.urlopen(req)
h=r.read()
print h
python3代码
import urllib.request
url='http://www.qiushibaike.com'
headers={
'user-agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36',
}
req=urllib.request.Request(url,headers=headers)
r=urllib.request.urlopen(req)
h=r.read()
print(h)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36')
添加header到对象.
效果预览
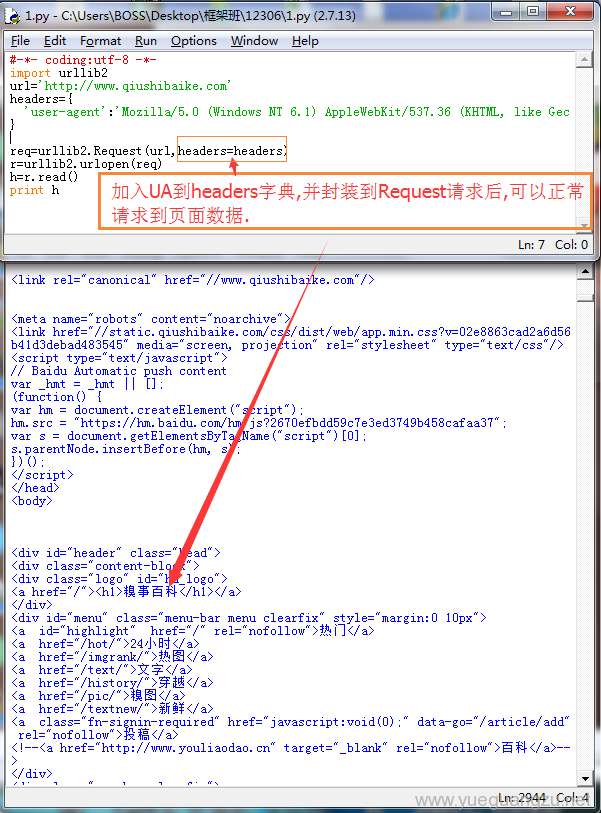
1.3geturl()的用法
-
geturl() — 返回检索的URL资源,这个是返回的真正url,通常是用来鉴定是否重定向的,常用来确定要获取那个最终的下载地址.
-
getcode() — 返回响应的HTTP状态代码,正常返回状态为code=200,如果返回值为302,说明发生了重定向。
1.4 HTTPCookieProcessor
很多网站需要登录,登录后的信息默认保存在cookies里.
很多网站的资源需要用户登录之后才能获取。
-
一般来说,用户在登录之后,服务器端会为该用户创建一个Session。Session相当于该用户的档案。该档案就代表着该用户。
-
那么某一次访问请求是属于该用户呢?登录的时候服务器要求浏览器储存了一个Session ID的Cookie值。每一个访问都带上了该Cookie。服务器将Cookie中的Session ID与服务器中的Session ID比对就知道该请求来自哪个用户了。
1.5 opener
我们在调用urllib2.urlopen(url)的时候,其实urllib2在open函数内部创建了一个默认的opener对象。然后调用opener.open()函数。但是默认的opener并不支持cookie。所以我们先新建一个支持cookie的opener。urllib2中供我们使用的是HTTPCookieProcessor。创建HTTPCookieProcessor需要一个存放cookie的容器。
Python提供的存放cookie的容器位于cookielib有以下几个:
CookieJar
FileCookieJar
MozillaCookieJar
LWPCookieJar
使用opener请求页面的一个例子
>>> import cookielib
>>> import urllib2
>>> cookies=cookielib.CookieJar()
>>> cookieHandler=urllib2.HTTPCookieProcessor(cookiejar=cookies)
>>> opener=urllib2.build_opener(cookieHandler)
>>> req=urllib2.Request('http://www.yueguangzu.net')
>>> r=urllib2.urlopen(req).read()
python3版本
>>> import http.cookiejar
>>> import urllib.request
>>> cookies=http.cookiejar.CookieJar()
>>> cookieHandler=urllib.request.HTTPCookieProcessor(cookies)
>>> opener=urllib.request.build_opener(cookieHandler)
>>> req=urllib.request.Request('http://www.yueguangzu.net')
>>> r=urllib.request.urlopen(req).read()
总结
urllib,urllib2是python自带的请求页面数据的模块,两者需结合使用,可以完成大部分的网页采集工作.涉及会话,则需要采用cookielib库创建带有cookie的opener完成请求.接下来的12306登陆,查询将会涉及到,所以需要熟悉掌握.
未经允许不得转载:http://www.yueguangzu.net
逗逗网 »
[12306专题]第一篇12306的urllib,urllib2


最新评论