1.再次处理12306的验证码
-
需要明确,12306的验证码是没有办法绕过.
-
目前仍没有什么模块可以进行解码
但这并不意味着,没有办法自动化识别验证码.这里采用第三方平台打码兔的方式进行在线解码.
-
解码平台提供2中解码方式,一种是直接将图片的url交给打码平台,让打码平台自己打开图片的地址,然后识别后,返回验证码的正确值.
-
第二种,是本地请求了图片,并把图片上传到打码平台,让平台根据图片返回正确的验证码.
-
由于验证码绑定session,所以采用第二种方法,现在本地请求到验证码图片,获得会话并绑定验证码,再将图片上传到打码平台解码后返回.
2.使用打码兔dama2.com进行在线解码
首先需要http://dama2.com/Index/ureg注册一个用户账号,账号需要验证手机号
注册完成后,需要接收短信验证码认证,同时需要至少先充值至少1元钱.
-
完成后,在验证码识别API接口维基,地址http://wiki.dama2.com/index.php?n=ApiDoc.Http界面,下载对应的API脚本,这里选择Python,对应下载地址[http://www.dama2.com/download/demo/damatuWeb-Python.zip](http://www.dama2.com/download/demo/damatuWeb-Python.zip)
-
打码兔提供的是python3的接口脚本,这里附上python2脚本damatuWeb.py,脚本需要修改的地方是末尾的dmt=DamatuApi("c******s","t*******0"),将刚才注册的打码兔的普通用户账号的用户名密码即可,需要注意的是,帐户里必须至少充1元钱,否则无法解码.
import hashlib
import http.client
import urllib2
import urllib
import json
import base64
def md5str(str):
m=hashlib.md5(str.encode(encoding = "utf-8"))
return m.hexdigest()
def md5(byte):
return hashlib.md5(byte).hexdigest()
class DamatuApi():
ID = '40838'
KEY = 'ca9507e17e8d5ddf7c57cd18d8d33010'
HOST = 'http://api.dama2.com:7766/app/'
def __init__(self,username,password):
self.username=username
self.password=password
def getSign(self,param=b''):
return (md5(bytes(self.KEY) + bytes(self.username) + param))[:8]
def getPwd(self):
return md5str(self.KEY +md5str(md5str(self.username) + md5str(self.password)))
def post(self,path,params={}):
data = urllib.urlencode(params).encode('utf-8')
url = self.HOST + path
response = urllib2.Request(url,data)
return urllib2.urlopen(response).read()
def getBalance(self):
data={'appID':self.ID,
'user':self.username,
'pwd':dmt.getPwd(),
'sign':dmt.getSign()
}
res = self.post('d2Balance',data)
res = str(res)
jres = json.loads(res)
if jres['ret'] == 0:
return jres['balance']
else:
return jres['ret']
def decode(self,filePath,type):
f=open(filePath,'rb')
fdata=f.read()
filedata=base64.b64encode(fdata)
f.close()
data={'appID':self.ID,
'user':self.username,
'pwd':dmt.getPwd(),
'type':type,
'fileDataBase64':filedata,
'sign':dmt.getSign(fdata)
}
res = self.post('d2File',data)
res = str(res)
jres = json.loads(res)
if jres['ret'] == 0:
return(jres['result'])
else:
return jres['ret']
def decodeUrl(self,url,type):
data={'appID':self.ID,
'user':self.username,
'pwd':dmt.getPwd(),
'type':type,
'url':urllib.quote(url),
'sign':dmt.getSign(url.encode(encoding = "utf-8"))
}
res = self.post('d2Url',data)
res = str(res)
jres = json.loads(res)
if jres['ret'] == 0:
return(jres['result'])
else:
return jres['ret']
def reportError(self,id):
data={'appID':self.ID,
'user':self.username,
'pwd':dmt.getPwd(),
'id':id,
'sign':dmt.getSign(id.encode(encoding = "utf-8"))
}
res = self.post('d2ReportError',data)
res = str(res)
jres = json.loads(res)
return jres['ret']
def codeCal():
code=dmt.decode('code.png',287)
code=code.replace('|',',')
code=code.split(',')
x=code[0::2]
y=code[1::2]
s=''
for i in zip(x,y):
y=int(i[1])-30
s+='%s,%s,'%(i[0],y)
return s[:-1]
dmt=DamatuApi("c******s","t*******0")
3.上传验证码解码
通过前面的脚本,我们下载了一张验证码图片code.png,和脚本文件存放在同一目录
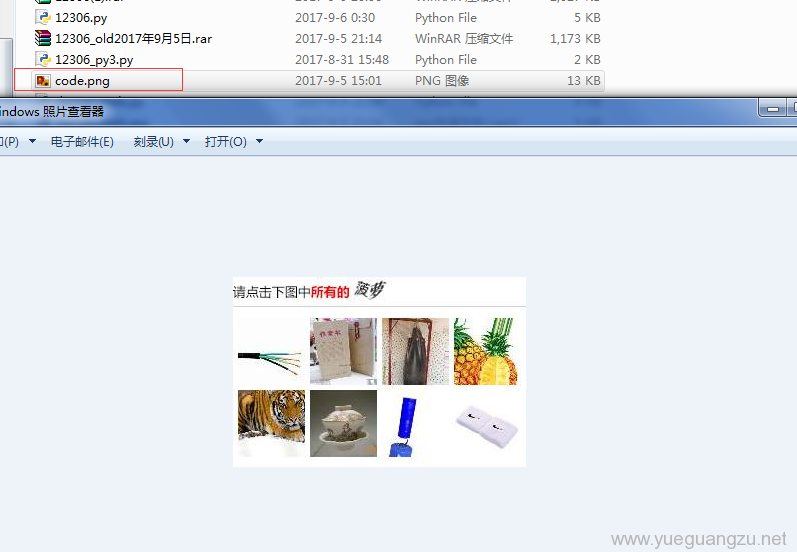
运行脚本后,得到上面的效果,上图菠萝只有一个,所以只有一对坐标点,说明解码是正确的.
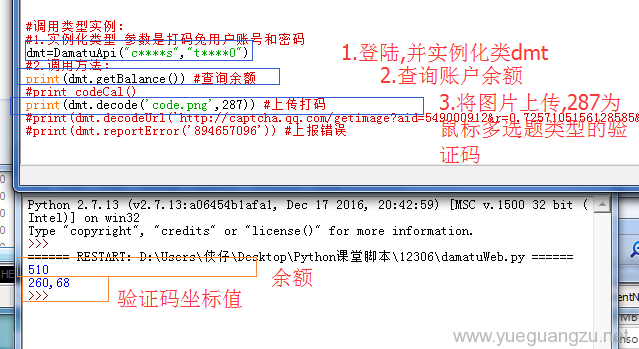
打码平台打码的默认起点,是从左上角最上面的顶点开始识别,而12306是从下方图片位置开始,这中间存在着纵坐标30像素的差距,所以需要自定义函数codeCal,进行修复
def codeCal():
code=dmt.decode('code.png',287)
code=code.replace('|',',')
code=code.split(',')
x=code[0::2]
y=code[1::2]
s=''
for i in zip(x,y):
y=int(i[1])-30
s+='%s,%s,'%(i[0],y)
return s[:-1]

4.将打码兔嵌入到12306模块
from __future__ import unicode_literals
import urllib,urllib2,ssl,cookielib,json,damatuWeb
c=cookielib.LWPCookieJar()
cookie=urllib2.HTTPCookieProcessor(c)
opener=urllib2.build_opener(cookie)
urllib2.install_opener(opener)
ssl._create_default_https_context=ssl._create_unverified_context
def getCode():
req=urllib2.Request('https://kyfw.12306.cn/passport/captcha/captcha-image?login_site=E&module=login&rand=sjrand')
codeimg=opener.open(req).read()
with open('code.png','wb') as f:
f.write(codeimg)
def code():
getCode()
code=damatuWeb.codeCal()
print(code)
data={
'answer':code,
'login_site':'E',
'rand':'sjrand',
}
data=urllib.urlencode(data)
req=urllib2.Request('https://kyfw.12306.cn/passport/captcha/captcha-check',data=data)
h=opener.open(req).read()
h=json.loads(h)
if h['result_code']=='4':
print(h['result_message'])
login()
else:
print(h['result_message'])
code()
def login():
data={
'username':'这里替换你的12306用户名',
'password':'这里替换你的12306密码',
'appid':'otn',
}
data=urllib.urlencode(data)
req=urllib2.Request('https://kyfw.12306.cn/passport/web/login',data=data)
h=opener.open(req).read()
h=json.loads(h)
if h['result_code']==0:
print(h["result_message"])
return True
else:
print(h["result_message"])
return False
if __name__=='__main__':
code()
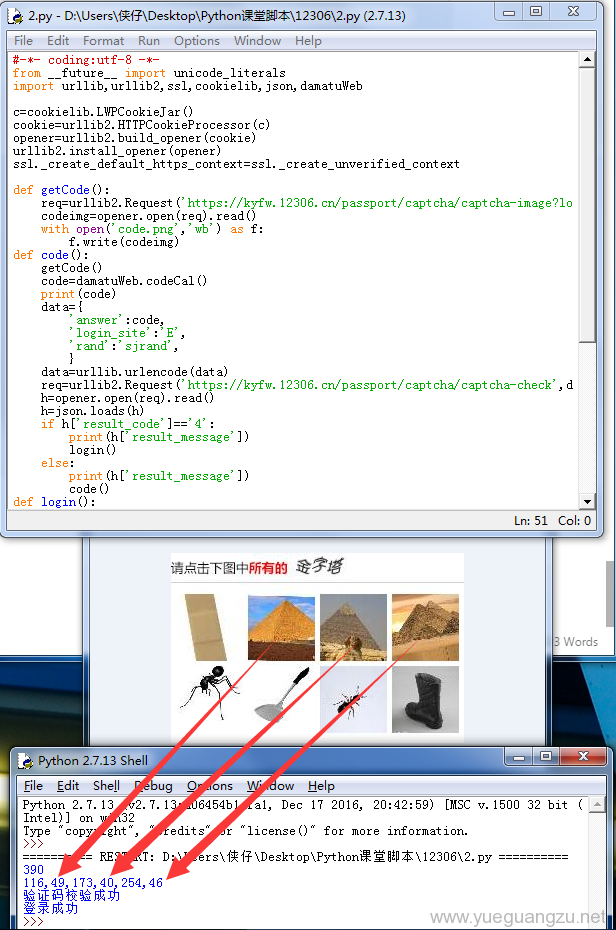
登陆成功,验证码通过后,登陆成功,整个过程大约5~6秒,解码速度还是令人满意的.
总结
本次重点分析了12306网站的验证码解码方式,由于不可绕过,所以采取了第三方解码的方式,既有效的降低了成本,还能很好解决验证码的问题,同时解码的效率还得到保证.修复验证码的逻辑对于今后的其它解码应用有很大帮助.所以请重点掌握该思路.



最新评论